Everyone who have worked with Lucene indexes in Sitecore probably asked one day him self – “how my content looks after tokenization process?”.
The answer of course is different depending on the type of used analyzer. (About types of analyzers you can read here. I will not provide those information here because it is not in the scope of this post)
Few days ago one of my colleagues (Wojciech Urban – thanks for that!), found the very useful tool which provide us following information:
- how tokenized text looks like
- how get tokens which are equal to those inside Lucene index
< You can find this tool here >
How tokenized text looks like?
As you can see in the image you are able to insert any description and test the tokenization process results.
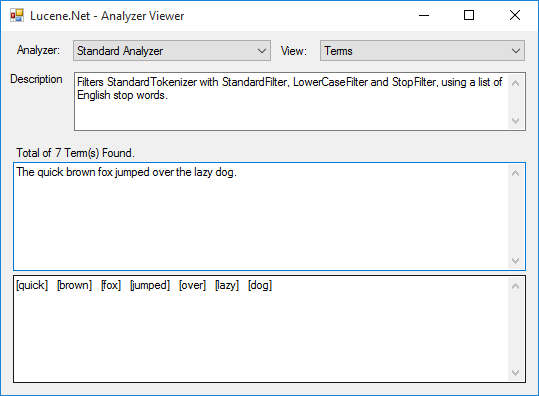
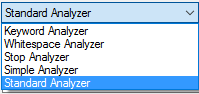
You can also change types of analyzers – you can choose from the following list:
With this tool, results of your queries would never surprise you again!
How to get tokens which are equal to those inside Lucene index?
If you need tokens – let say for do something with your search results you can do something like this:
// get the analyzer which you use
var analyzer = new StandardAnalyzer(Version.LUCENE_30);
// prepare StringReader object with your text inside
StringReader stringReader = new StringReader(text);
// get the tokens stream
TokenStream tokenStream = analyzer.TokenStream("defaultFieldName", stringReader);
while (tokenStream.IncrementToken())
ITermAttribute termAtt = tokenStream.AddAttribute<ITermAttribute>();
var term = termAtt.Term;
// ...
// ... do something with your term
// ...
}